
Data and Methodology
The CUHK Electronic Theses and Dissertations (“ETD”) is a large collection of digitized graduate theses from postgraduate students across all disciplines of CUHK, hosted by the CUHK Library; it is one of the Digitised Collections and can be accessed here. It dates back to the beginnings of CUHK in the mid-1960s, and consists of both full text in pdf files as well as metadata of each thesis. The files are publicly accessible and can be downloaded.
Below is an example of one of the theses in the ETD (Fig. 1).
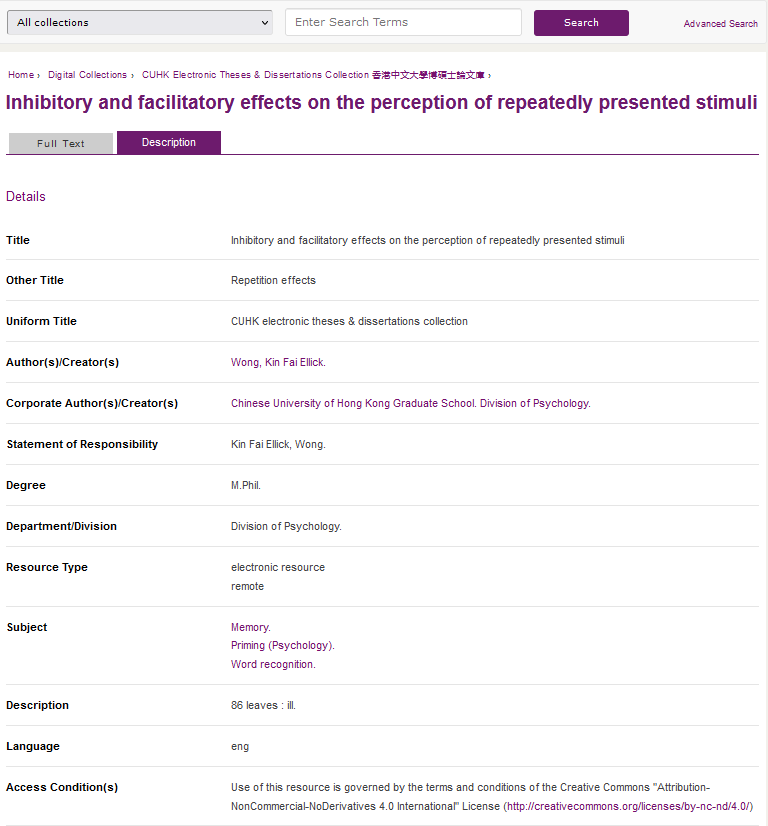
The metadata generally provides information on the theses title and the subjects it covers, the author, supervisors and their affiliation, the degree type, language, among a few other more technical details.
For the purpose of this analysis for the Data Analytics Practice Opportunity, we made use of the theses metadata, containing thesis title, subjects, authorship information, the departments/divisions, language, and graduation year. Several other fields were discarded. For the automatic mass download of the collection entries, we used the resumption token of the CUHK Digital Repository, provided by the library.
Below is an example for the data structure after retrieving the data.
<record>
<header>
<identifier>oai:cuhk-dr:cuhk_321953</identifier>
<datestamp>2023-04-27T17:56:00Z</datestamp>
<setSpec>cuhk_etd</setSpec>
</header>
<metadata>
<oai_dc:dc xmlns:oai_dc="http://www.openarchives.org/OAI/2.0/oai_dc/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/oai_dc/ http://www.openarchives.org/OAI/2.0/oai_dc.xsd">
<dc:title>Inhibitory and facilitatory effects on the perception of repeatedly presented stimuli.</dc:title>
<dc:title>Repetition effects</dc:title>
<dc:subject>Memory</dc:subject>
<dc:subject>Priming (Psychology)</dc:subject>
<dc:subject>Word recognition</dc:subject>
<dc:description>Kin Fai Ellick, Wong.</dc:description>
<dc:description>Thesis (M.Phil.)--Chinese University of Hong Kong, 1997.</dc:description>
<dc:description>Includes bibliographical references (leaves 74-83).</dc:description>
<dc:contributor>Wong, Kin Fai Ellick.</dc:contributor>
<dc:contributor>Chinese University of Hong Kong Graduate School. Division of Psychology.</dc:contributor>
<dc:date>1997</dc:date>
<dc:type>Text</dc:type>
<dc:type>bibliography</dc:type>
<dc:format>print</dc:format>
<dc:format>86 leaves : ill. ; 30 cm.</dc:format>
<dc:identifier>cuhk:321953</dc:identifier>
<dc:identifier>http://library.cuhk.edu.hk/record=b5889345</dc:identifier>
<dc:language>eng</dc:language>
<dc:rights>Use of this resource is governed by the terms and conditions of the Creative Commons “Attribution-NonCommercial-NoDerivatives 4.0 International” License (http://creativecommons.org/licenses/by-nc-nd/4.0/)</dc:rights>
<dc:identifier>https://repository.lib.cuhk.edu.hk/en/item/cuhk-321953</dc:identifier>
</oai_dc:dc>
</metadata>
</record>The metadata for each thesis was extracted and stored in an .xml file. The different information was contained by the opening delimitator <…> and ended by </…>.
Description
Certain elements were systematically extracted from the existing text data and factorized or retained as numeric variables. Tab. 1 below shows their distribution, whereas the processing and distribution of the text variables can be found in the next section.
| Variable | Categories | Description |
| Date | 1967-2021 | Publication year of thesis |
| Language | English Chinese | Binary for the primary thesis language |
| Degree | Masters Degree PhD Degree | Binary for the degree level the thesis was written for |
| Departments/Divisions (Top 10) | School of Life Sciences CUHK Business School Dep. of Physics Dep. of Computer Science and Engineering Dep. of Chemistry Fac. of Education Dep. of Electronic Engineering Dep. of Medicine and Therapeutics Dep. of Information Engineering Dep. of Mathematics [+46] | Categorical variable for the affiliated departments. In a few cases a further distinction into the departments was not possible based on the metadata. |
| Faculty | Fac. of Science Fac. of Engineering Fac. of Social Science Fac. of Arts Fac. of Medicine CUHK Business School Fac. of Education Fac. of Law | Categorical variable for the home faculty of the departments/divisions. |
| Academic Area | STEM Social Sciences Humanities | Categorical variable for the academic area of the faculties. |
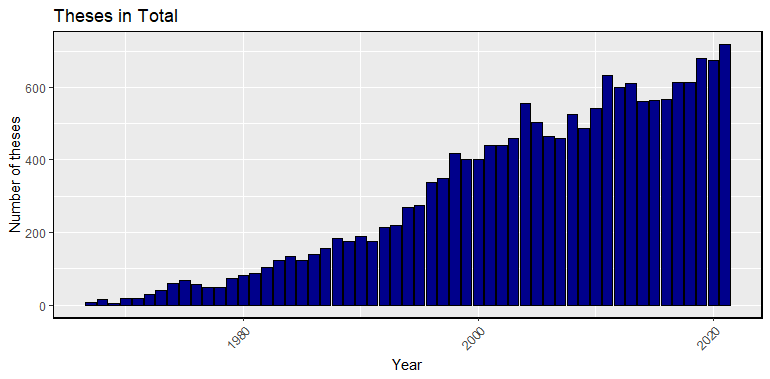
The frequency distribution of the theses available by year indicates a left-skewed distribution, with an almost continuous increase in the number of theses by later years. For the first ten years (1967-1976), 315 theses are in the edited ETD dataset, compared to 6,200 for the last ten years of the analysis (2012-2021). The increase appears rather linear with little tendency of outlier years (Fig. 2).
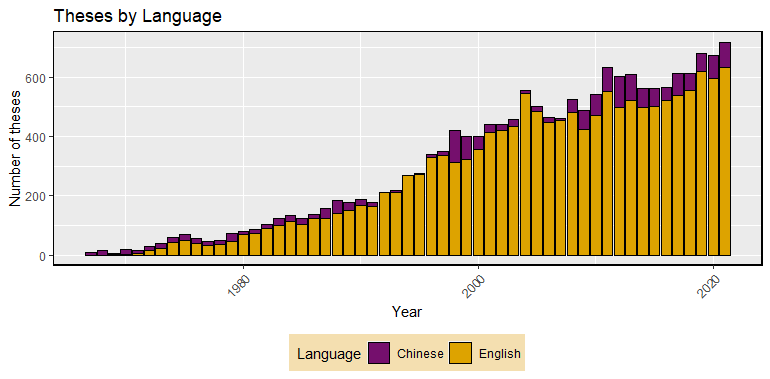
Highlighting the share of English and Chinese language theses, we can clearly observe the higher prevalence of theses written in English (Fig. 3). Over the last around ten years, the ratio of English-to-Chinese language theses seems to remain more or less stable, with a clear majority of theses written in English.
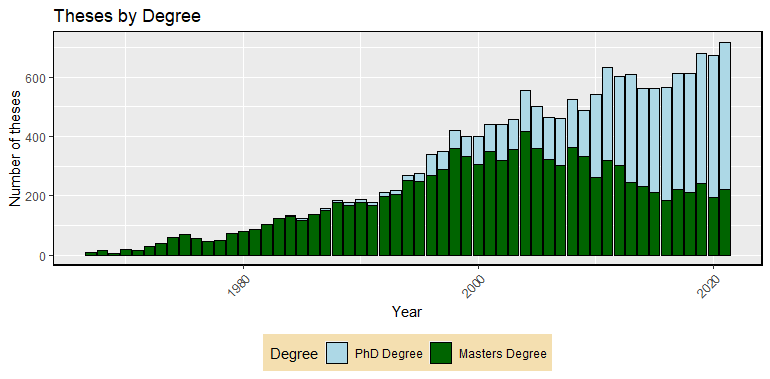
We see a diverging trend in the last years, with the number of PhD theses in the ETD growing, while the number of Masters theses seeing a decline (Fig. 4). This becomes particularly visible after the year 2009.
From the metadata, the information of the departments/divisions – mainly department, but also schools or programs – was extracted (Tab. 2). For the theses written in the faculty of education and the faculty of law, a further classification was not possible from the information from the metadata.
| Departments/Divisions | Number of Theses | Share |
| School of Life Sciences | 1,731 | 8.9 |
| CUHK Business School | 1,674 | 8.6 |
| Dep. of Physics | 931 | 4.8 |
| Dep. of Computer Science and Engineering | 825 | 4.2 |
| Dep. of Chemistry | 807 | 4.1 |
| Fac. of Education | 785 | 4.0 |
| Dep. of Electronic Engineering | 738 | 3.8 |
| Dep. of Medicine and Therapeutics | 667 | 3.4 |
| Dep. of Information Engineering | 643 | 3.3 |
| Dep. of Mathematics | 632 | 3.2 |
| Dep. of Economics | 559 | 2.9 |
| School of Architecture | 551 | 2.8 |
| Dep. of Chinese Language and Literature | 512 | 2.6 |
| Dep. of Psychology | 491 | 2.5 |
| Dep. of History | 486 | 2.5 |
| Dep. of Systems Engineering and Engineering Management | 468 | 2.4 |
| Dep. of Mechanical and Automation Engineering | 397 | 2.0 |
| Dep. of Cultural and Religious Studies | 392 | 2.0 |
| Dep. of Statistics | 388 | 2.0 |
| School of Biomedical Sciences | 367 | 1.9 |
| Dep. of English | 342 | 1.8 |
| Dep. of Sociology | 336 | 1.7 |
| Dep. of Philosophy | 302 | 1.5 |
| Dep. of Anatomical and Cellular Pathology | 287 | 1.5 |
| School of Journalism and Communication | 278 | 1.4 |
| Dep. of Geography and Resource Management | 269 | 1.4 |
| Dep. of Social Work | 204 | 1.0 |
| Dep. of Music | 191 | 1.0 |
| Dep. of Surgery | 191 | 1.0 |
| Dep. of Government and Public Administration | 190 | 1.0 |
| Dep. of Fine Arts | 183 | 0.9 |
| Dep. of Anthropology | 165 | 0.8 |
| The Jockey Club School of Public Health and Primary Care | 162 | 0.8 |
| Nethersole School of Nursing | 149 | 0.8 |
| Dep. of Chemical Pathology | 143 | 0.7 |
| Dep. of Orthopaedics and Traumatology | 138 | 0.7 |
| Gender Studies Program | 101 | 0.5 |
| School of Chinese Medicine | 100 | 0.5 |
| Dep. of Obstetrics and Gynaecology | 86 | 0.4 |
| School of Pharmacy | 86 | 0.4 |
| Dep. of Linguistics and Modern Languages | 83 | 0.4 |
| Dep. of Microbiology | 70 | 0.4 |
| Dep. of Opthalmology and Visual Sciences | 64 | 0.3 |
| Dep. of Translation | 58 | 0.3 |
| Dep. of Biomedical Engineering | 47 | 0.2 |
| Earth System and Geoinformation Sciences Program | 46 | 0.2 |
| Dep. of Imaging and Interventional Radiology | 42 | 0.2 |
| Fac. of Law | 42 | 0.2 |
| Div. of Earth and Environmental Sciences | 38 | 0.2 |
| Centre for China Studies | 37 | 0.2 |
| Dep. of Anaesthesia and Intensive Care | 37 | 0.2 |
| Dep. of Japanese Studies | 33 | 0.2 |
| The School of Accountancy | 9 | 0.0 |
| Dep. of Marketing | 4 | 0.0 |
| Dep. of Finance | 1 | 0.0 |
| The Divinity School of Chung Chi College | 1 | 0.0 |
| Missings | 954 | 4.9 |
| 19,513 | 100 |
The above departments were further manually allocated to their home faculties (Tab. 3).
| Faculty | Number of Theses | Share |
| Faculty of Science | 4,643 | 23.8 |
| Faculty of Engineering | 3,118 | 16.0 |
| Faculty of Social Science | 3,016 | 15.5 |
| Faculty of Arts | 2,748 | 14.1 |
| Faculty of Medicine | 2,519 | 12.9 |
| CUHK Business School | 1,688 | 8.7 |
| Faculty of Education | 785 | 4.0 |
| Faculty of Law | 42 | 0.2 |
| Missings | 954 | 4.9 |
| 19,513 | 100 |
In a last step, they were categorized according to the commonly used academic macro-area. We acknowledge that there are different views about certain classifications. Moreover, different academic traditions can lead to different self-identification of a department. (Tab. 4).
| Academic Area | Number of Theses | Share |
| STEM | 10,280 | 52.7 |
| Social Sciences | 5,489 | 28.1 |
| Humanities | 2,790 | 14.3 |
| Missings | 954 | 4.9 |
| 19,513 | 100 |
Unsupervised Natural Language Processing
For a latent topic model analysis it is assumed that within a body of different texts, there are undetected or hidden – “latent” – topics, through which the texts are connected. Treating texts as word vectors with one word as a unit, simple topic models calculate the correlations between each vector. For each text – in our case the word vectors from the titles and the keywords – the proportion of each topic to be present can then be calculated. If the model calculates the presence of a latent topic to be highly likely in a text, it will be assigned a value approximating 1; if it is highly unlikely, it will approximate 0.
At the beginning, we applied the conventional editing steps for common bag-of-words models on the levels of words.
- Non-ASCII characters, numbers, and any form of punctuation symbols were excluded from the data, as they are non-interpretative or functional to a sentence.
- Additional white spaces were limited to a single space, capitalized letters were made to lowercase letters.
In the second step, additional word groups which were irrelevant were excluded, as they generally are also non-interpretative or residual characters from earlier editing:
- Single isolated letters, numerals, and roman numerals.
- Auxiliary verbs in all tenses.
- All pronouns, conjunctions, and prepositions, according to official English language lists.
- Time words, including weekdays, times of the day, and months.
- Words that refer to the structure or goal of a thesis, rather than their content, such as “review” or “hypothesis”.
- Words in pinyin.
We also removed duplicated words, e.g. those that appeared both in the title and in the keywords. Finally, we also applied the stopword list of R (Version 2023.09.1), and stemmed the words. After transforming the text data into a document-term-matrix, we calculated a Correlational Topic Model for 15 latent topics, and derived the topic-per-document prevalence for each theses. If the predicted probability exceeded a 0.5 threshold, it was assigned a 1, if not it received a 0. The distribution of the dichotomized topic prevalence were used to constructed the edge weights for the network visualizations.