
Embedding Paragraphs into a Vector Space
To facilitate semantic exploration of the classical Daoist texts, each paragraph is embedded into a high-dimensional vector space. In this space, paragraphs with similar meanings are positioned closer to one another. The embedding process leverages the pre-trained model “BAAI/bge-large-zh-v1.5” from the Beijing Academy of Artificial Intelligence, which outputs a 1024-dimensional vector for each paragraph. This robust representation allows the system to capture subtle semantic nuances from the texts.
3D Projection Visualization
For interactive exploration and analysis, the high-dimensional embeddings are projected into a three-dimensional space using TensorBoard. The visualization panel is designed with the following capabilities:
- Interactive Navigation:
Users can zoom, rotate, and pan the 3D projection to explore the spatial relationships among the paragraphs. - Search and Highlight:
The interface allows users to search for specific paragraphs and highlight them within the visualization, making it easy to locate texts of interest. - Similarity Exploration:
Users can select a paragraph and instantly locate the k most similar paragraphs based on Euclidean or cosine distance within the vector space.

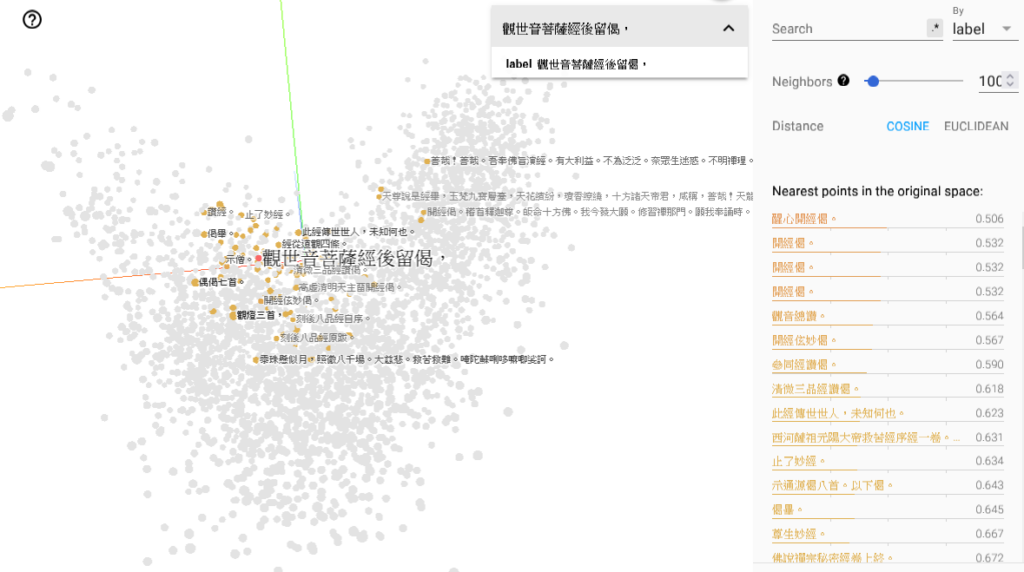
Fig 1, 2: Example use of TensorBoard
Value and Contributions
The 3D visualization of the embedding space significantly enhances the understanding of the textual corpus:
- Enhanced Textual Analysis:
For scholars and researchers in digital humanities, the projection enables an intuitive understanding of how various paragraphs relate semantically. The spatial clustering provides insights into thematic patterns and narrative structures that might be less obvious through standard text retrieval methods. - Facilitated Discovery:
By interacting with the visualized embedding space, users can quickly discover closely related passages that may have been dispersed across large volumes of text. This aids not only in academic research but also in teaching and digital archive exploration. - Improved Retrieval and Feedback:
The ability to visually inspect the embedding space and the proximity of text segments supports the refinement of the similarity search algorithm. Users can evaluate the clustering and adjust parameters if needed, leading to more accurate retrieval results. - Supporting Cross-Disciplinary Collaboration:
Historians, literary scholars, and computational linguists can all benefit from an interactive platform that bridges qualitative analysis and quantitative methods. The system provides a common ground where numerical vector analysis meets traditional textual interpretation.